
The Agentic AI Digest (26/09)| Giving Your Agent a Brain with Gemini & Understanding Model Temperature
This week: We connect our Go agent to its first LLM, demystify the 'temperature' setting for controlling creativity, and explore why the new DORA report calls AI an 'amplifier' of team performance.

Hi everyone,
Welcome to your weekly briefing from the Agentic AI Roundtable. Our goal is to cut through the noise and deliver the most relevant signals, patterns, and community wins to help you build more effectively.
Let’s dive in.
🛠️ Community Commits: Building in the Open
The A2A agent build continues! After setting up the gRPC server foundation last week, it’s time to give our agent its brain. This week’s “Watch Me Build” connects our Go implementation to a Large Language Model for the first time, enabling true conversational ability.
Follow along as we implement the core SendMessage RPC, integrate Google’s Gemini model via the Vertex AI Go SDK, and watch our agent handle its first end-to-end conversational turn—from user query to an LLM-powered response.
Watch Me Build: A2A Agent in Go - Part 3: Connecting to Gemini & Implementing SendMessage
Useful links
📒From the Workbench: Patterns to Pocket
This week, we’re continuing our deep dive into model configuration. Besides ‘thinking,’ another important parameter to understand is temperature. Adjusting it gives you fine-grained control over the creativity and consistency of your model’s outputs.
How it Works: The Softmax Function
LLMs generate text sequentially, one token at a time. For each new token, the model outputs a vector of numbers called logits. These logits represent the raw, unnormalized prediction scores for every possible token in the model’s vocabulary. The logits are then converted into a probability distribution from which the model samples to output the new token.
To convert these scores into a probability distribution, the model uses a modified softmax function. The temperature parameter (T) is introduced into this function to scale the logits before the final probability calculation. The probability of a given token, pi is calculated as:
where:
zi is the logit for token i.
T is the temperature parameter.
The sum in the denominator is taken over all tokens j in the vocabulary.
Thus, setting the temperature effectively changes the shape of the probability distribution for selecting the new token. When T is a small value (like 0), the probability distribution approaches a state where the token with the highest logit has a 100% chance of being selected, while every other token has a 0% chance. For higher values of T, the distribution is more uniform, and the tokens have a more equal chance of being selected.
When to Use It:
Practically, temperature can be thought of as the measure of ‘creativity’ or randomness that the model has. Lower temperature values mean more deterministic responses, and higher temperature values translate into more random responses:
Low Temperature (0.0): Use this for debugging and reproducibility. A temperature of 0 ensures that for a given prompt, the output will be identical every time, eliminating randomness as a variable.
Low-to-Moderate Temperature (0.1 - 0.7): Ideal for tasks requiring factual consistency and reliability, like summarization, translation, or generating code.
High Temperature (0.8 - 2.0): Good for applications that require more ‘creativity’, like brainstorming or writing fiction. Also good for when subsequent responses using the same input data must produce a different output (e.g., a regenerate button).
In the code:
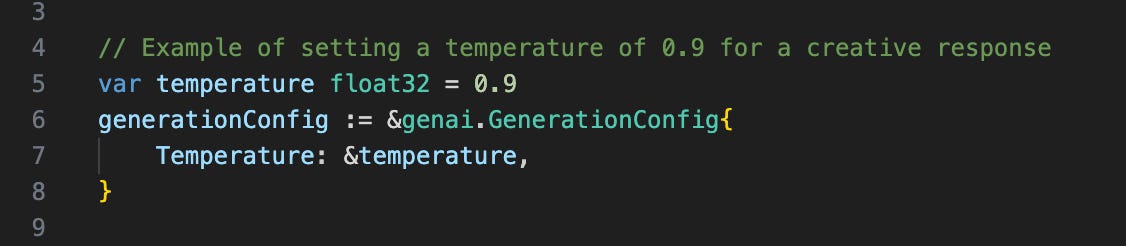
Just as in last week’s article, the temperature is easily set through the GenerationConfig of your API request. Our example is with the Gen AI Golang SDK:
Further Resources for Learning More:
Good theoretical explanation:
https://medium.com/@kelseyywang/a-comprehensive-guide-to-llm-temperature-%EF%B8%8F-363a40bbc91f
Official Google Documentation on parameters: https://cloud.google.com/vertex-ai/generative-ai/docs/learn/prompts/adjust-parameter-values
Gen AI Golang SDK: https://pkg.go.dev/google.golang.org/genai
📡 On the Radar: What’s Moving the Needle
A curated look at the articles, papers, resources and updates that are worth your time this week.
AI as an Amplifier, Not a Magic Wand: The latest DORA “State of AI-assisted Software Development” report is out, and it’s a must-read for any engineering leader. The core finding? AI’s primary role is that of an amplifier. It magnifies the strengths of high-performing teams and the dysfunctions of struggling ones. The report argues that the biggest returns on AI investment don’t come from the tools themselves, but from a strategic focus on the underlying system: the quality of your internal platform, the clarity of your workflows, and the alignment of your teams. Without this foundation, you’re just creating pockets of productivity that get lost in downstream chaos.
Under the Hood of AI Coding Agents: For those who want to move from being a consumer of AI to a producer, a fantastic new article from Ampcode, “How to Build an Agent,” breaks down the fundamentals. It demystifies the process, showing that a powerful agent is essentially an LLM in a loop with access to tools. It’s a practical, hands-on guide that will change how you think about agentic systems.
Highlights from the Google AI Builders Forum: Google recently hosted its AI Builders Forum, and it was packed with insights. A key highlight was the demo of the new Gemini CLI, an open-source AI agent that brings Gemini directly into your terminal. You can watch the full event, including the demo, on-demand.
🤝 Want to Get Involved in the Community?
This roundtable is driven by its members. To join the conversation, share your work, or ask a question, you have two great options:
Join our private Google Chat space for real-time discussions and to participate in the weekly Open Thread. [Link to Chat Space]
Send a message to our community Google Group at roundtable-community@agentic-ai.build.
We look forward to hearing from you.
The Agentic AI Roundtable Core Team