
The Agentic AI Digest (23 January 2026) | Multimodal ingestion for Gemini
...

Hi everyone,
Welcome to your weekly briefing from the Agentic AI Roundtable. Our goal is to cut through the noise and deliver the most relevant signals, patterns, and community wins to help you build more effectively. Let’s dive in.
A Guide to Multimodal Ingestion: Building a Production-Grade Pipeline
Building production-grade AI applications requires a robust strategy for handling diverse user data. Whether a user uploads a PDF, a voice note, a recorded meeting, technical diagrams, or complex spreadsheets, our systems must transform raw bytes into structured data that a Large Language Model (LLM) can effectively reason over. This process is known as Multimodal Ingestion.
In a production environment, multimodal ingestion involves far more than simply passing raw files to an API. During my time at Alis, I developed an event-driven, four-stage multimodal ingestion pipeline for our product, Ideate. Over the next few weeks, we will cover each stage in detail. While our solution (depicted below) is highly effective for scale, it is not the only approach; we will explore alternative designs and trade-offs depending on specific requirements.
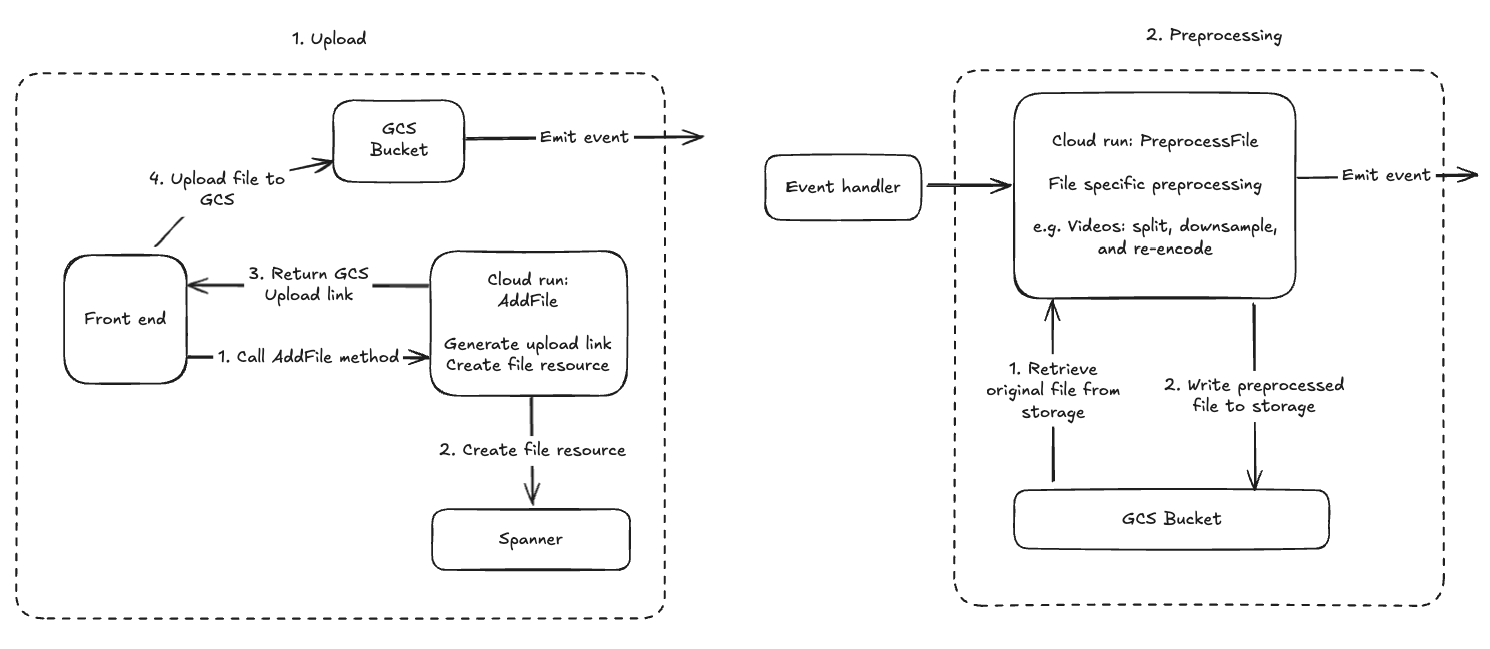
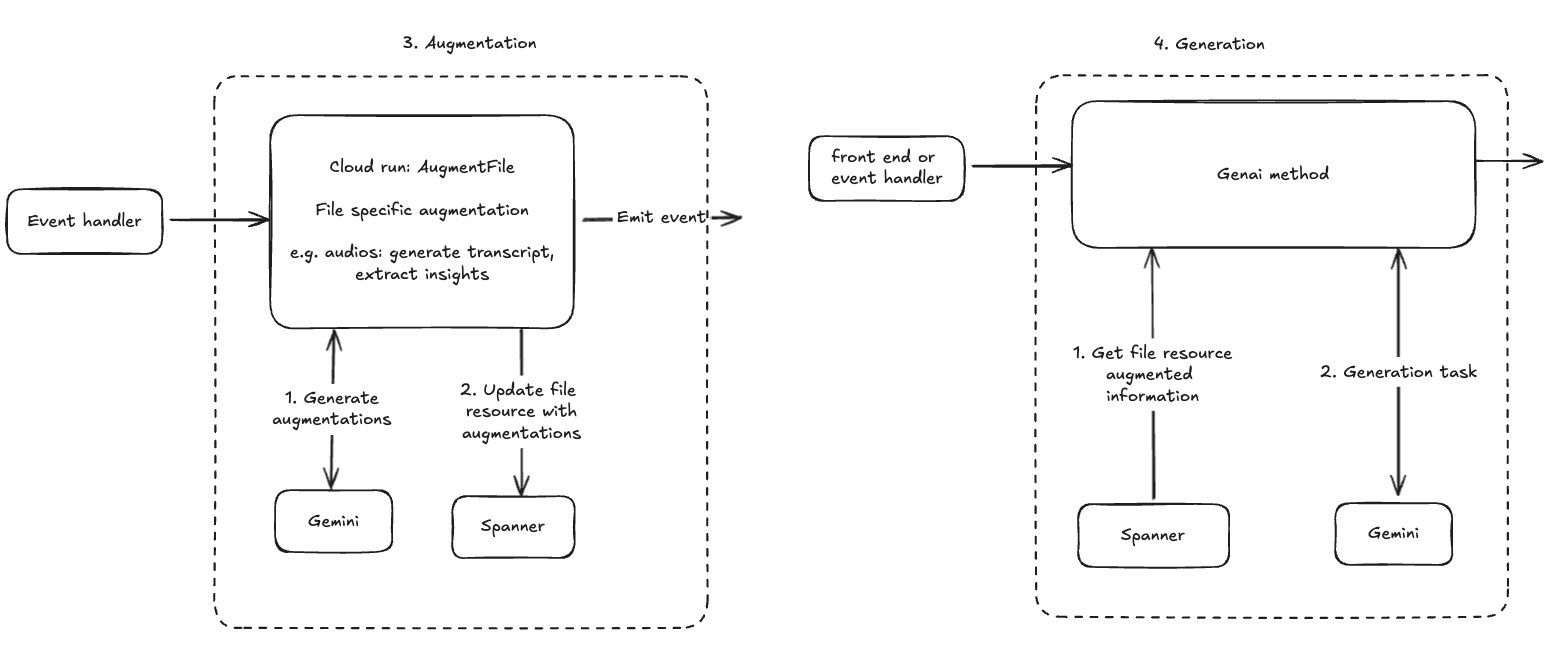
The Four Stage Architecture
Four stages might seem like overkill, but we’ve found it to be necessary to handle data reliably at scale. This architecture ensures that our system is modular, scalable, and easy to maintain.
Stage 1: File Upload
This is the entry point. To prevent the main application server from being throttled by large binary transfers, we decouple the transport of the file from its processing. The frontend coordinates with the backend to securely move the file into a storage bucket (e.g., Google Cloud Storage) via signed URLs. Simultaneously, we initialize a record in our primary database (e.g., Google Spanner) to track the file’s state throughout the pipeline.
Stage 2: Preprocessing
Once stored, the file is optimized for model consumption. This stage performs file-specific transformations to achieve three goals:
Compatibility: We convert unsupported formats into LLM-friendly types (e.g., converting proprietary formats or extracting text from legacy Word docs).
Token Efficiency: We reduce costs and latency by downsampling high-bitrate audio and high-resolution video where the extra fidelity doesn’t aid reasoning.
Parallelization: To overcome model limitations—such as long-context window reliability or generation speed—we segment large files. For example, if a model struggles with 60-minute videos, we split them into 5-minute chunks to process augmentations in parallel.
Stage 3: Augmentation
Before the file is used in a final generative task, we use an LLM to extract metadata and structural insights. The goal is to provide focused context. Passing a 500-page document to every subsequent prompt is inefficient and "bloats" the context window. Instead, we extract the document's structure, section headings, and summaries. This "augmented" metadata is stored in the file resource and serves as the primary context for downstream calls.
Stage 4: Generation
Following the first three stages, all subsequent calls to Gemini involving the uploaded file use the augmentations associated with the file, rather than the file itself.
The Case for Decoupled Architecture
By separating these stages using an event-driven pattern (e.g., Pub/Sub), the system gains significant production advantages:
Fault Tolerance
Isolating Cascading Failures: In a coupled system (standard REST calls), a failure in the augmentation stage might cause the entire upload request to hang or fail. In an event-driven setup, each stage operates independently. If Stage 3 fails, the system can retry that specific task without requiring the user to re-upload the file.
Event Queuing: If a downstream service is temporarily offline or undergoing deployment, upstream services can still succeed by emitting an event. Once the downstream service recovers, it simply picks up where it left off.
Independent Service Scaling
Rate Limiting as a “Shock Absorber”: Pub/Sub allows us to process events at a controlled rate, protecting our quotas and limits during traffic spikes.
Resource Optimization: Some stages are more resource-intensive than others. For example, our video preprocessing service requires specialized GPU hardware. By decoupling, we can scale our CPU-based servers independently of our GPU-backed workers.
Extensibility
A decoupled architecture allows for easier integration of new components. As requirements evolve, we can easily insert new steps into the pipeline—such as sensitive data (PII) redaction, anti-malware scanning—without refactoring the core logic.
Looking Ahead
In the coming weeks, we’ll dive deeper into the technical implementation of each stage, starting with file uploads. Join us as we explore how to build AI systems that don’t just work, but scale.
🤝 Want to Get Involved in the Community?
This roundtable is driven by its members. To join the conversation, share your work, or ask a question, you have two great options:
Join our private Google Chat space for real-time discussions and to participate in the weekly Open Thread. [Link to Chat Space]
Send a message to our community Google Group at roundtable-community@agentic-ai.build.
We look forward to hearing from you.
The Agentic AI Roundtable Core Team